This appendix provides an overview of the data sources and analytic approaches used in the report.
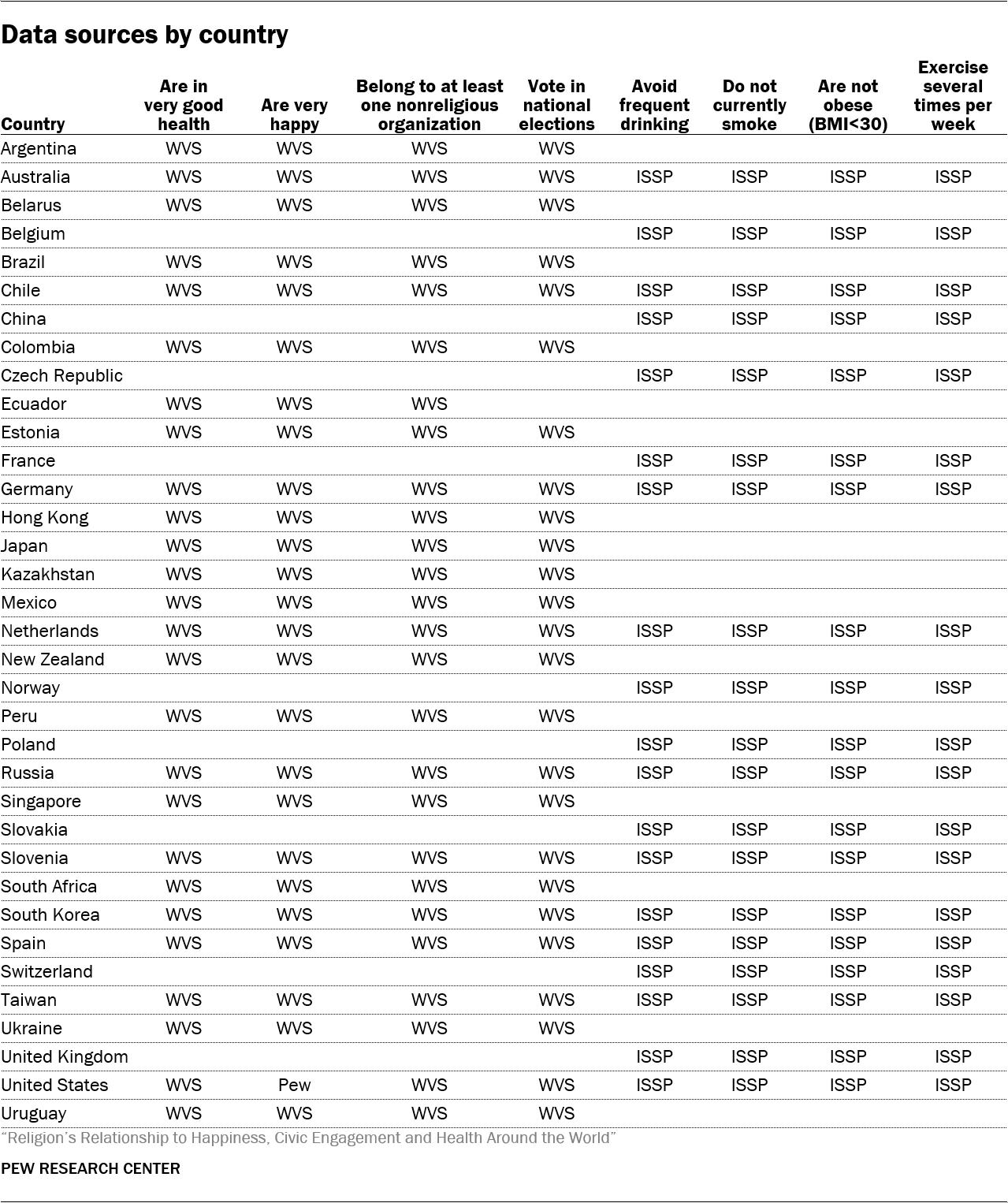
The general population data underlying this study were sourced from three survey datasets: The World Values Survey (WVS) Wave 6 (2010-2014), the International Social Survey Programme (ISSP) 2011 Health and Health Care Module, and one 2012 Pew Research Center survey of U.S. adults on gender and generations. The Pew Research Center survey provides U.S. estimates for self-rated happiness (and an additional 2013 Pew Research Center survey provides data on self-rated health for the sidebar on the U.S.) while the WVS and ISSP provide international comparisons. Pew Research Center chose these survey datasets because they are well-established sources of data that include the relevant measures for this report. The WVS and ISSP contribute different measures: The WVS contains measures of self-rated health, happiness, voting and membership in secular voluntary organizations, while the ISSP contains measures of smoking, drinking alcohol, obesity and exercise.
The World Values Survey is an international network of survey researchers headquartered in Stockholm, Sweden. The WVS, which has been conducted since 1981, includes nationally representative survey data for about 100 countries worldwide. In each participating country, members of the World Values Survey Association field a survey and share the data with the network. Two years later, those data are made publicly available. When this report was written, the sixth wave of the WVS was the most current dataset available to the public. The WVS Wave 6 survey data were collected between 2010 and 2014.
The International Social Survey Programme is an international research collaboration that places a common core of survey questions on nationally representative surveys in 45 countries. For instance, in the United States, the ISSP data are sourced from the General Social Survey, a periodic survey of the American public conducted by NORC at the University of Chicago. In each country, survey organizations place translations of the same set of questionnaire items on their survey ballots. The data are then compiled and made available online for download. In 2011, the ISSP included a special module on health and health care. The health characteristic data for this report (smoking, drinking, exercise and BMI) were sourced from this module.
When calculating estimates for each country listed in this report, Pew Research Center only included countries with at least 100 survey respondents in each of three categories: the actively religious, inactively religious and religiously unaffiliated. For this reason, many countries in the World Values Survey or ISSP are not included in this report.
When estimating the shares of the population that are actively religious, inactively religious and religiously unaffiliated, researchers compared estimates from the WVS and ISSP to other nationally representative data, including survey data collected by Pew Research Center. In most cases, the various sources of data produced similar estimates. However, in three cases, the estimates were different enough that researchers excluded countries from the analyses. In the World Values Survey, about 10% of respondents in Nigeria, Rwanda and the Philippines are religiously unaffiliated, and about half of these respondents attend religious services at least monthly. Such estimates are markedly different from those obtained by other nationally representative surveys of these countries, and the reasons for the discrepancies are not clear. Therefore, Nigeria, Rwanda and the Philippines are excluded from the analyses in this report.
Methods
When comparing the actively religious, inactively religious and religiously unaffiliated, this report presents as statistically significant those differences for which the null hypothesis of no differences between the groups can be rejected with a 95% level of confidence. All differences at the country level have been tested for statistical significance, and the country-level differences mentioned in the text of this report are statistically significant unless noted otherwise.
Actively religious, inactively religious and religiously unaffiliated
One objective of this analysis was to determine the extent to which religious identity versus religious involvement is linked to well-being. Prior research suggests that active participation in the social life of a religious community – rather than self-identification alone – predicts many of the benefits attributed to religion, such as health and happiness. For this reason, researchers chose to parse the survey respondents into three categories: actively religious, inactively religious and religiously unaffiliated. Throughout the report, the actively religious are those who identify with a religion and attend religious services at least once per month (similar patterns were observed when the threshold of weekly attendance was used). The inactively religious are those who identify with a religion but attend less than once per month. And the religiously unaffiliated are those who do not identify with a religion.
It is important to note that in the survey data used in this report, respondents chose their level of religious attendance from a short list of options. Rather than reporting exactly how many times they had attended worship within some time interval, respondents placed themselves into categories such as weekly, monthly, a few times a year or never. Monthly attendance was chosen as the marker for active religious involvement because it separates occasional attenders from regular attenders.
There are some religiously unaffiliated survey respondents who report that they attend religious services monthly or more. They are counted as unaffiliated and grouped with the rest of the unaffiliated who attend infrequently or never. However, unaffiliated people who attend monthly or more are rare – not numerous enough to substantively alter the patterns reported in this analysis. In other words, if the “nones” who attend monthly were included as “actively religious,” the broad patterns described in this report would not change.
Only in two countries in this analysis are there more than 100 unaffiliated respondents in the sample who attend religious services at least monthly. In Ecuador, 124 of the 282 unaffiliated respondents report that they attend monthly or more, and in South Africa, 145 of the 542 unaffiliated respondents report this level of religious attendance. And although they attend more frequently than their counterparts, the “nones” who attend services at least monthly in these countries are not clearly distinct in terms of their well-being. In South Africa and Ecuador, high-attending “nones” do not differ significantly from other “nones” in their likelihood of saying they are very happy or very healthy. In South Africa (but not Ecuador), high-attending “nones” are more likely to be active in at least one nonreligious organization.
Regression analyses
The regression analyses in this report were estimated using logistic regressions on data from either the World Values Surveys (WVS) or the International Social Survey Programme (ISSP), depending on the measure. The results shown in the data visualizations of Appendix C and the pooled regression analysis in the body of the report are percentage-point differences in the predicted probabilities between the actively religious and the rest of the population (the unaffiliated plus the inactively religious). The predicted probabilities assume all other covariates are fixed at their means for a given level of analysis (where the mean represents either the average for all the survey respondents from all countries pooled together in the pooled analysis, or the average for survey respondents from a particular country for the country-specific analysis). The following paragraphs provide more detail.
Dependent variables
For most of the well-being measures shown in the report (e.g., health, happiness, smoking), researchers dichotomized an ordinal variable. For instance, researchers recoded the ISSP measure of smoking from an ordered seven-category variable to a binary measure where 1 codes for not smoking any amount, and 0 codes for all other valid responses. In each case, researchers cut the ordinal variable at thresholds that correspond roughly to desirable health outcomes. For example, our binary measure of smoking indicates when the respondent totally abstains from smoking, but the variable for drinking codes for avoidance of “frequent” (several times per week or more) drinking rather than total abstinence, which may have a less pronounced effect on health. 52 The only dependent variable that was originally continuous was our measure of body mass index (BMI), which we calculated using data on the respondents’ height and weight from the ISSP.53 Our obesity measure indicates when the respondent has a body mass index above 30 – the level defined as obesity by the World Health Organization and the U.S. Centers for Disease Control and Prevention.
Independent variables
All the predictors in the regression models were dichotomized to simplify the presentation of results. The indicators of age (younger or older than 40) and sex (male or female) can be straightforwardly understood and interpreted.54 The other indicators are described below.
Actively religious. The focal predictor in the regression models is whether the respondent is actively religious (i.e., identifies with a religion and attends religious services at least monthly). Rather than make three separate comparisons between the actively religious, inactive and unaffiliated, the regressions simply compare the actively religious to the rest of the population. This is the case for all of the regression models displayed graphically in the report. However, an entirely separate set of regression models compare the inactive and unaffiliated. Those models omit the actively religious from the sample and test whether religious affiliation (in the absence of regular attendance) contributes to well-being. These alternate models are sometimes referenced in the text of the report.
Above median income. The WVS and the ISSP provide income data differently from one another. The WVS provides income data transformed into 10 groups, which are presumed to represent country-specific income deciles. Although these deciles have been criticized for misrepresenting country-level income distributions, this analysis is constrained by the measures that are available in the data.55 Respondents are classified as above-median earners if they fall above the fifth decile. The ISSP provides untransformed income categories specific to each country. Respondents are considered to earn above the median income if they fall into a category that is higher than the median value for all the survey respondents in their country.
Completed college or tertiary education. The education categories differ between the WVS and ISSP. For regressions using the WVS data, this indicator codes for whether the respondent has completed “university-level education, with degree.” For regressions using the ISSP data, this indicator codes for whether the respondent has completed “lower-level tertiary” education or higher.
Married or cohabiting. The WVS indicates whether respondents are married (versus cohabiting or separated); in contrast, the ISSP indicates only if the respondent has a “steady partner,” and, if so, whether the respondent lives with their partner. For regressions on the WVS data, “married or cohabiting” indicates whether the respondent is married or cohabiting (but not widowed or separated). For regressions using the ISSP data, “married” codes for whether the respondent is in a partnership and also lives with their partner.
In some cases, variables are omitted from the regression models because data are unavailable. Specifically, data on marital status are unavailable in the United Kingdom. In Appendix C (which displays separate regression results for each country), the marriage variable is dropped for the row marked “United Kingdom.” And in the pooled regression model (marked “all countries”), the UK does not contribute to the point estimates because of listwise deletion of cases. Additionally, in the regression models predicting drinking behavior in Chile, the gender variable is omitted because of its collinearity with drinking (after dropping the cases with missing data on the other covariates, there are no remaining women in the Chile sample who drink frequently). Finally, in the regression models estimating the differences between the inactive and unaffiliated, the gender variable is omitted in Chile and Slovakia, and the education predictor is omitted for Slovakia, all due to collinearity with other variables.
Predicted probabilities, significance tests and weighting
The results shown in the data visualizations are differences in the marginal effects at the mean (MEM) between the actively religious and the rest of the population. To compute the MEMs, we first estimated regression models and used the prediction equations from the models to estimate the shares of the actively religious (and the rest of the population) who fall into the category of interest (e.g., those who do not smoke). The marginal effect calculations assume that all the control variables are fixed at their means. In regression analyses that include all of the countries pooled together, covariates are fixed at their grand means (i.e., the mean for all the respondents in the dataset with valid responses). For regression analyses using data from just one country (as in Appendix C), covariates are fixed at their mean for that particular country. Researchers then subtracted the predicted value for the combined inactive and unaffiliated populations from the actively religious population to obtain a percentage-point difference. As a robustness check, we also calculated average marginal effects (AMEs) and marginal effects assuming covariates fixed at 0 and recomputed the percentage-point differences. The results from the alternative calculations were nearly identical to those computed using MEMs.
For the regression results here and in Appendix C, each estimate for the predicted influence of a variable is attached to a significance test. The data visualizations indicate when the p-value corresponding to a predicted value is less than 0.05. These significance tests were calculated as part of the marginal effect calculations. Each significance test is based on robust standard errors that account for within-country clustering among the pooled WVS or ISSP respondents.
All descriptive statistics and point estimates from regression models were calculated using the standard post-stratification weights provided with the WVS and ISSP (post-stratification weights are not available for some WVS countries). However, for the regression models, researchers reweighted the data to assume equal representation from each country because, for instance, the ISSP contains more than 3,000 respondents from Belgium, but only 936 from the United Kingdom. To avoid overrepresenting the patterns in Belgium or underrepresenting those from the UK, we divided the standard post-stratification weights by the total number of respondents in each country, which we then multiplied by 1,000 to assume 1,000 respondents per country in the regressions.
